Agentic Behavior: How to Build Reliable AI Agents for Operations

When we started building AI systems for incident analysis at Hyground, we made a classic mistake: we wrote incredibly detailed prompts. Step-by-step instructions. Decision trees. Edge case handling. The prompts got longer. The results got worse.
It took us a while to understand why.
The Maze Problem
Incident analysis isn't like following a recipe. It's like navigating a maze. You don't know which path leads to the root cause until you've explored it. Each discovery changes where you should look next. The number of steps is unknown, and the next step depends entirely on what you just learned.
This is where traditional prompting breaks down. A prompt runs before you've learned anything. You can't write instructions for a maze you haven't seen yet.
This is also where AI agents come in.
What Makes an Agent Different
A chatbot is reactive: prompt in, response out, done. An agent runs in a loop.
The pattern, called ReAct (Reasoning + Acting), looks like this:
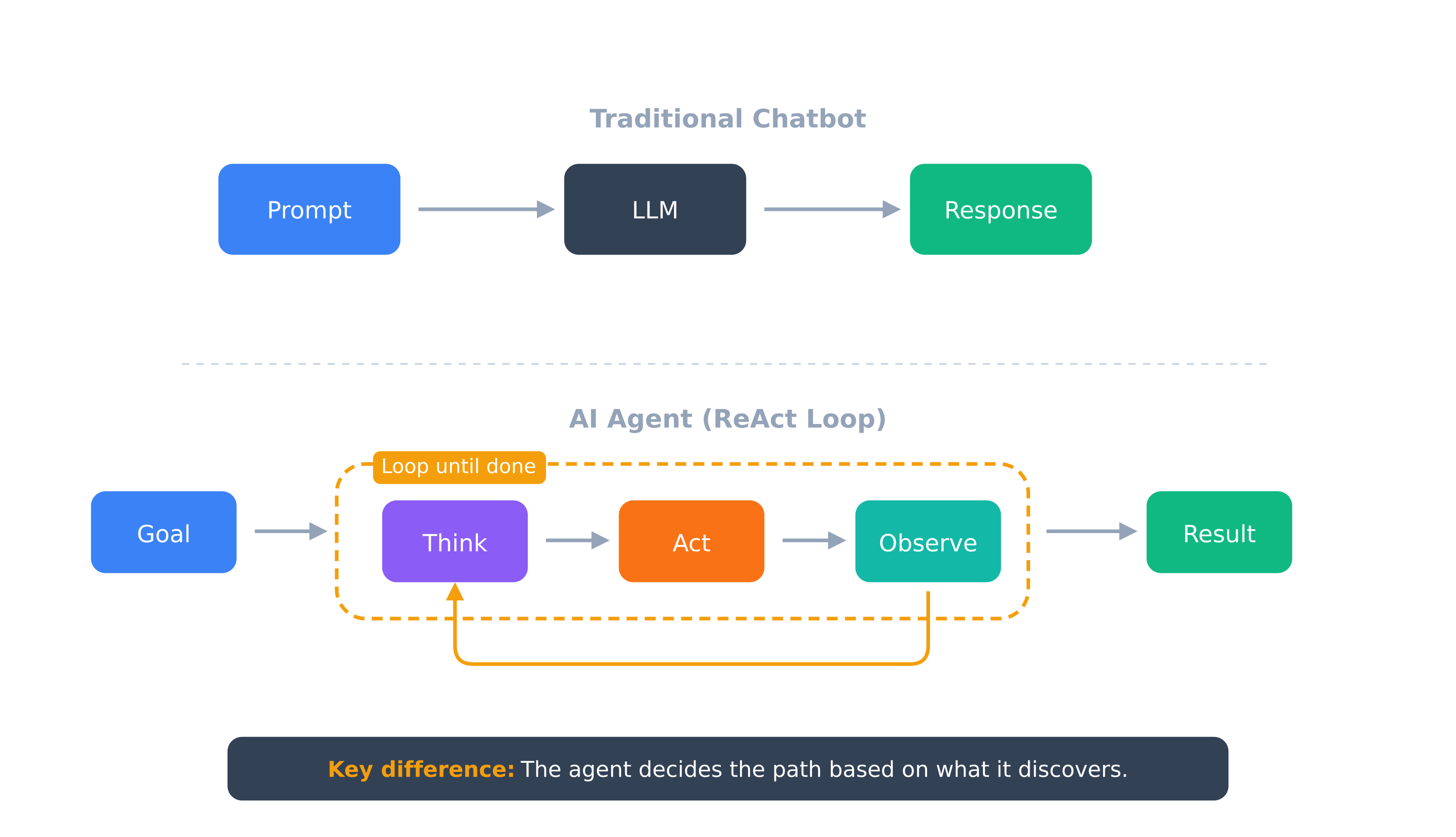
Chatbot: one pass, path decided upfront. Agent: multiple passes, path discovered at runtime.
The agent queries a tool, interprets the result and decides what to do next. It might check logs, find something suspicious, query a related service, discover a dependency and trace that upstream. All without being told the specific steps in advance.
Anthropic puts it clearly: agents handle "open-ended problems where it's difficult or impossible to predict the required number of steps." If you could write out all the steps, you'd have a workflow. When you can't, you need an agent.
An Agent Investigation in Practice
Here's a simplified example from our system. A monitoring alert fires: API latency spiked to 2.3s.
StepThinkActObserve1Latency spike—check which endpoints are affectedQuery metrics API/checkout endpoint, others normal2Single endpoint—could be downstream service or databaseCheck checkout service logsConnection timeouts to payment service3Payment service issue—check its healthQuery payment service metricsHealthy, low latency4Payment service fine but connections timing out—network or connection pool?Check connection pool metricsPool exhausted, 0 available connections5Pool exhausted—what's holding connections?Query active transactions47 transactions stuck waiting on fraud_check6Found it—why is fraud_check hanging?Check fraud serviceDeployed 23 min ago, new version has deadlock
Root cause: A deployment introduced a deadlock. Six steps, path unpredictable from the start.
A prompt can't encode "if payment service is healthy but connections timeout, check connection pools, then trace what's holding them." Each step depends on what the previous one revealed.
Why Longer Prompts Make Things Worse
Here's what surprised us: the more detailed our prompts got, the worse the results became. Three reasons:
1. You're encoding an algorithm for a problem that doesn't have one
Complex investigation isn't algorithmic. When you write a 2000-word prompt trying to cover every scenario, you're essentially telling the LLM "here's exactly how to solve this" for a problem that requires exploration and judgment. The LLM follows your rigid instructions instead of reasoning about what it actually observes.
2. Attention is a budget, and you're spending it on instructions
LLMs don't treat all text equally. Research shows they recall information at the beginning and end of prompts better than the middle. Every "IMPORTANT" and "CRITICAL" you add to steer attention actually drains the attention budget. With a multi-page prompt, the model struggles to focus on what matters in the actual problem.
3. Context windows aren't as big as they seem
We covered this in our post on MCP context composition. 87% of our context window was consumed by tool definitions alone. Add a verbose prompt, intermediate results from each tool call and you've exhausted your usable context before the interesting work begins.
A study from 2024 shows that reasoning performance degrades around 3,000 tokens. This is well below technical limits. Context is precious working memory, not unlimited storage. Since the publication the performance degradation has improved a lot, but the principle still holds true. Coding agents for example force context compaction, well before hitting the actual context limit.
What Actually Works
The key insight: don't tell the agent how to solve the problem. Give it the tools and let it reason.
Short, focused prompts that define the goal and constraints. Not the algorithm. The agent figures out the path.
This requires:
- Tool access: APIs, databases, log systems the agent can query
- Clear stopping conditions: When is the task complete?
- Guardrails: What actions require human approval?
For incident analysis, this means giving the agent access to observe logs, query metrics and trace dependencies. Then letting it investigate. It might take 3 steps or 30. The agent decides based on what it finds.
The Limits Are Real
We're not claiming agents solve everything. Current LLMs like Opus 4.5, Gemini 3 and GPT-5.x are on the brink of handling complex investigation tasks reliably. They excel at information gathering and iterative refinement. They struggle with truly novel reasoning.
Reliability is an ongoing challenge. The same prompt can produce different results on different runs. Errors in early steps compound downstream. Production systems need comprehensive observability and human oversight for high-stakes decisions.
What's Next
Single-agent architectures hit a ceiling when problems get big. Context fills up. The investigation scope exceeds what one agent can track.
The solution is multi-agent systems. Specialized agents that collaborate, each with focused context and clear responsibilities. We'll cover the patterns for orchestrating multiple agents in our next posts.

The latest from our team
Explore stories on DevOps, AI, and enterprise security

Ready to transform your operations
See how Hyground reduces incident response time and strengthens your security posture
