Agents
A multi-agent system that plans, investigates, and decides. Specialised agents work logs, metrics, and knowledge in parallel, then aggregate what they find into one answer.
Architecture
A signal arrives, agents investigate in a sandboxed workspace, and the result lands in the tools your team already runs. Every step happens inside your own infrastructure, on the model you choose.
The whole picture
Inbound adapters carry alerts, chats, and messages into Hyground. Agents reason over them, act in a sandboxed shell, and draw on your runbooks and past investigations. What comes back is a filed ticket, written documentation, or an answered thread. Nothing leaves your cluster.
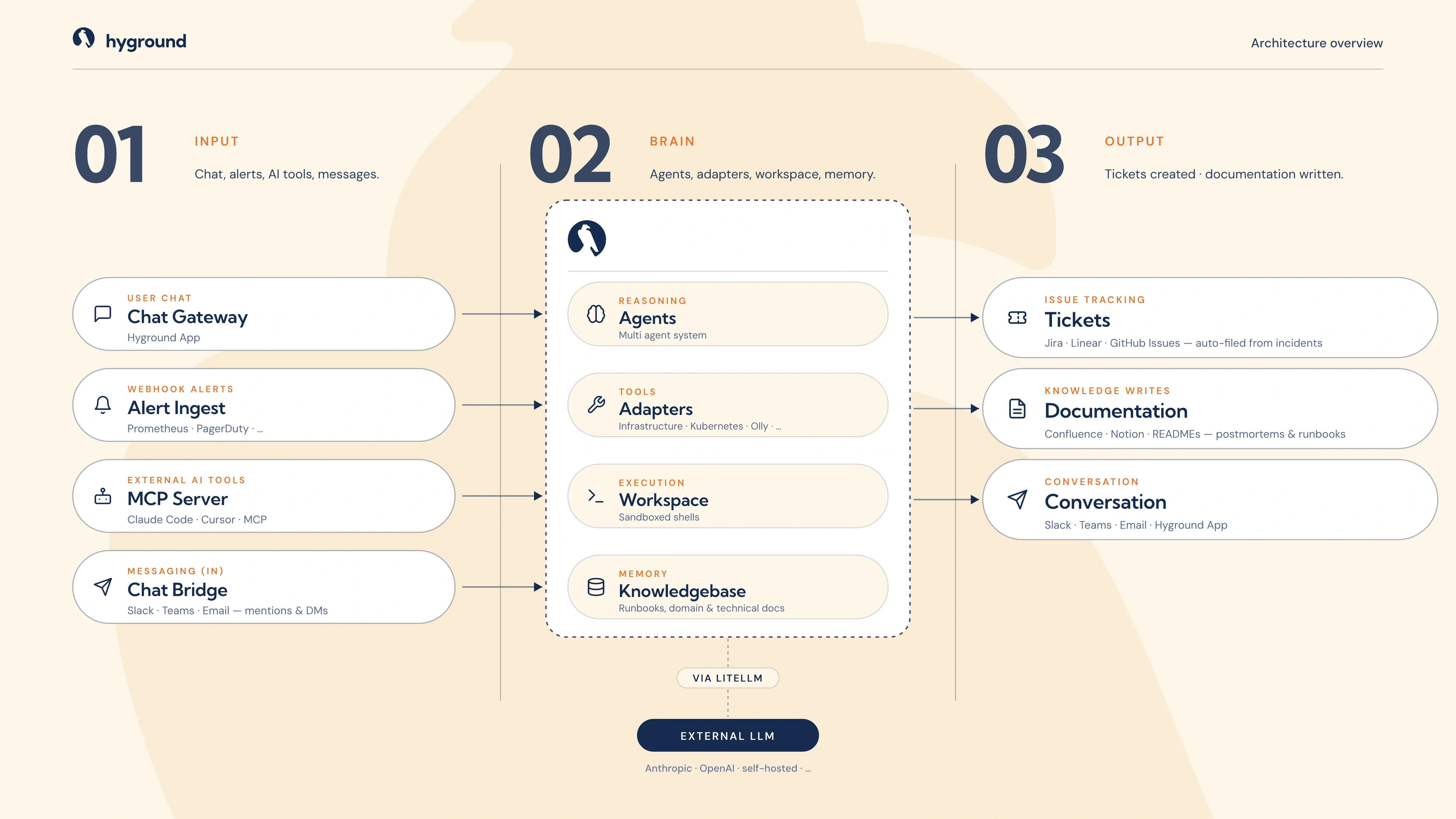
Agents reach their model through LiteLLM, so the choice stays yours: Anthropic, OpenAI, Google, or a model you host yourself. Swap providers without touching the rest of the system. No vendor lock-in, no data sent to a model you didn't pick.
Four parts do the work: agents that reason, adapters that read your systems, a sandbox where they act, and a memory of how you operate.
A multi-agent system that plans, investigates, and decides. Specialised agents work logs, metrics, and knowledge in parallel, then aggregate what they find into one answer.
Hardened, read-only wrappers around the tools you already trust: Kubernetes, cloud, observability, databases. They refuse to start if the principal can write.
A sandboxed shell where the agents do the actual work. Each task runs in an isolated container with a fixed set of pre-authenticated CLIs: kubectl, logcli, promtool, psql. Nothing else.
Your runbooks, documentation, and past investigations, embedded for retrieval. Agents recall how your systems work and how you fixed things last time.
A real run
What it takes to get from an alert to a structured root cause, with and without Hyground in the loop.
Alert fires. The on-call engineer is paged and starts switching between dashboards.
Logs and metrics opened in separate tabs. Manual filtering for the affected service starts.
Cross-team Slack thread spun up to find someone who knows the service and the recent changes.
Timestamps correlated by hand across logs, traces and deployment history.
A likely root cause emerges after trial and error and a hunt through old incident notes.
Findings written up manually. The Jira ticket is filed and the post-mortem is scheduled.
Total time: around 3 hours
Heavily dependent on who is on-call and what they remember from the last similar incident.
An alert arrives at the ingest endpoint. The payload passes an injection and jailbreak check before any work starts.
The agent plans the investigation and executes it.
Logs, metrics, traces and deployment history are queried in parallel from a read-only execution environment.
Relevant runbooks and past investigations are pulled from the knowledge base, so the reasoning is grounded in how your systems actually work.
A structured root cause is delivered: affected services, supporting evidence, recommended next actions, every step recorded.
A post-mortem draft is written automatically from the investigation: timeline, root cause, contributing factors, action items.
Time to root cause: around 6 minutes
Every step runs inside your cluster. Every query, every piece of evidence, every reasoning step is recorded and replayable.
The same loop plugs into the tools your team already lives in, inbound and outbound.
Alerts, chats, and AI tools reach Hyground through inbound adapters.
Findings come back as work, not notifications, in the tools your team already uses.
Self-hosted & sovereign
Hyground ships as a Kubernetes Helm chart and runs entirely inside your perimeter. There is no Hyground SaaS in the path: no control plane, no phone-home, no operator access into your cluster.
A self-hosted Helm chart with no vendor access path. No SaaS control plane, no central key, no shared infrastructure. The vendor has no operational route in.
Zero data egress, zero telemetry, no phone-home. The only outbound traffic is the prompt to the LLM you chose, and secrets are stripped before the model sees them. Host that model yourself and nothing leaves at all.
Chainguard distroless images, non-root, read-only root filesystem. Adapters are read-only by default and refuse to start if the principal can write.

Check out our sandbox or schedule a demo with our team and experience sovereign AI firsthand.