Agenten
Ein Multi-Agenten-System, das plant, untersucht und entscheidet. Spezialisierte Agenten bearbeiten Logs, Metriken und Wissen parallel und führen ihre Ergebnisse zu einer einzigen Antwort zusammen.
Architektur
Ein Signal geht ein, Agenten untersuchen es in einem abgeschotteten Workspace, und das Ergebnis landet in den Tools, mit denen Ihr Team ohnehin arbeitet. Jeder Schritt läuft in Ihrer eigenen Infrastruktur, auf dem Modell Ihrer Wahl.
Das Gesamtbild
Inbound-Adapter bringen Alerts, Chats und Nachrichten zu Hyground. Agenten analysieren sie, handeln in einer abgeschotteten Shell und greifen dabei auf Ihre Runbooks und frühere Untersuchungen zurück. Zurück kommt ein fertiges Ticket, eine geschriebene Dokumentation oder ein beantworteter Thread. Nichts verlässt Ihren Cluster.
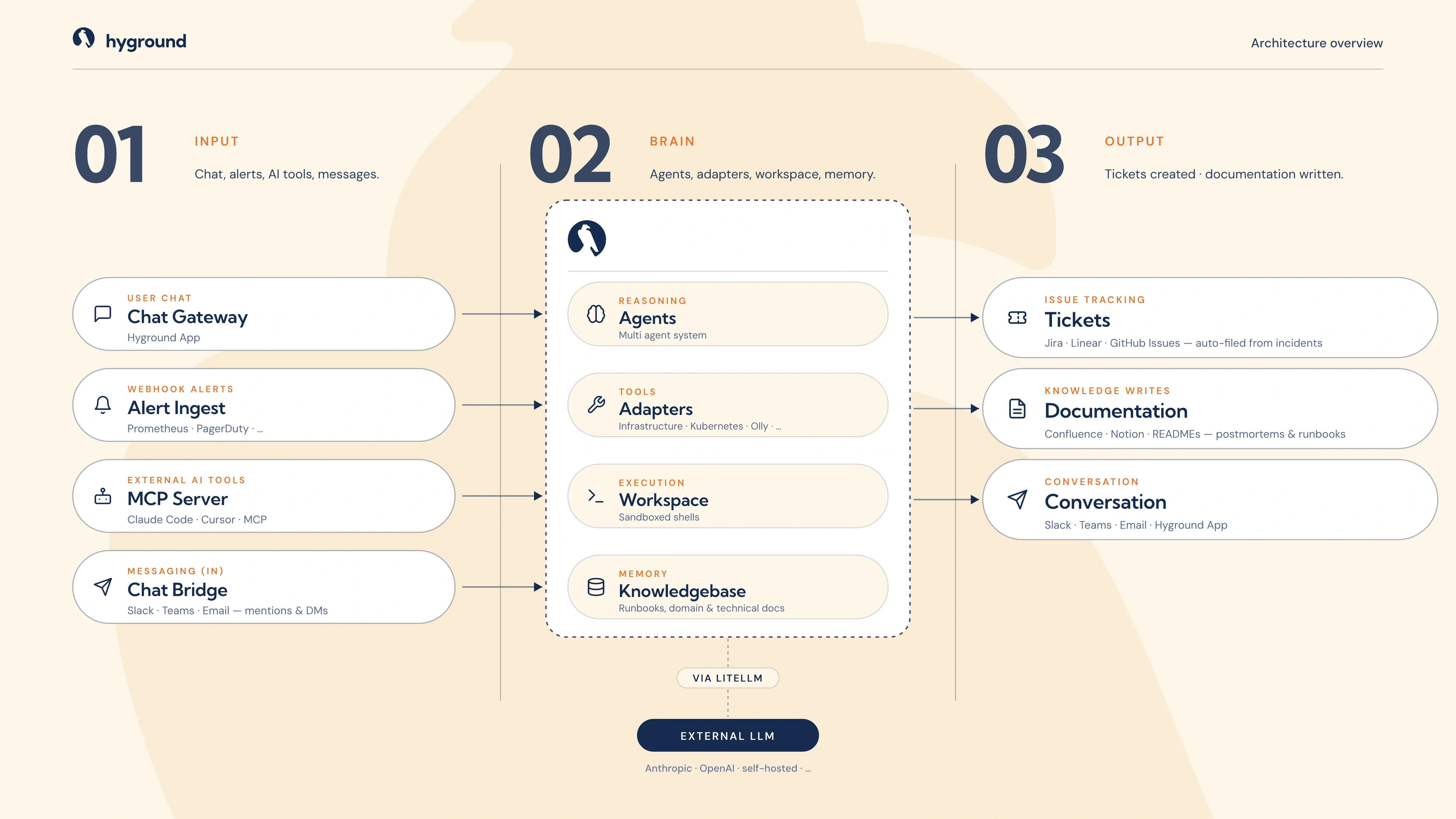
Agenten erreichen ihr Modell über LiteLLM, die Wahl liegt also bei Ihnen: Anthropic, OpenAI, Google oder ein Modell, das Sie selbst hosten. Wechseln Sie den Anbieter, ohne am Rest des Systems etwas zu ändern. Kein Vendor-Lock-in, keine Daten an ein Modell, das Sie nicht selbst gewählt haben.
Vier Bausteine erledigen die Arbeit: Agenten, die analysieren, Adapter, die Ihre Systeme auslesen, eine Sandbox, in der sie handeln, und ein Gedächtnis dafür, wie Sie arbeiten.
Ein Multi-Agenten-System, das plant, untersucht und entscheidet. Spezialisierte Agenten bearbeiten Logs, Metriken und Wissen parallel und führen ihre Ergebnisse zu einer einzigen Antwort zusammen.
Gehärtete, schreibgeschützte Wrapper um die Tools, denen Sie ohnehin vertrauen: Kubernetes, Cloud, Observability, Datenbanken. Sie verweigern den Start, wenn der Principal schreiben darf.
Eine abgeschottete Shell, in der die Agenten die eigentliche Arbeit erledigen. Jede Aufgabe läuft in einem isolierten Container mit einem festen Satz vorauthentifizierter CLIs: kubectl, logcli, promtool, psql. Sonst nichts.
Ihre Runbooks, Ihre Dokumentation und frühere Untersuchungen, eingebettet für den Abruf. Agenten erinnern sich, wie Ihre Systeme funktionieren und wie Sie ein Problem beim letzten Mal gelöst haben.
Ein echter Durchlauf
Was es braucht, vom Alert zur strukturierten Ursache zu kommen: mit und ohne Hyground im Spiel.
Alert feuert. Die diensthabende Person wird gepiept und springt zwischen Dashboards hin und her.
Logs und Metriken werden in einzelnen Tabs geöffnet. Manuelles Filtern nach dem betroffenen Service beginnt.
Ein cross-team Slack-Thread wird aufgemacht, um jemanden zu finden, der den Service und die letzten Änderungen kennt.
Zeitstempel werden manuell zwischen Logs, Traces und Deployment-Historie korreliert.
Nach Trial-and-Error und einer Suche in alten Incident-Notizen taucht eine wahrscheinliche Ursache auf.
Die Ergebnisse werden manuell verschriftlicht, das Jira-Ticket wird angelegt, das Post-Mortem terminiert.
Gesamtzeit: rund 3 Stunden
Stark abhängig davon, wer dienstlich erreichbar ist und was diese Person aus dem letzten ähnlichen Vorfall erinnert.
Ein Alert trifft am Ingest-Endpoint ein. Die Payload durchläuft eine Injection- und Jailbreak-Prüfung, bevor irgendetwas startet.
Der Agent plant die Untersuchung und führt sie aus.
Logs, Metriken, Traces und Deployment-Historie werden parallel aus einer schreibgeschützten Ausführungsumgebung abgefragt.
Passende Runbooks und frühere Untersuchungen werden aus der Wissensdatenbank gezogen, das Reasoning ist in Ihren Systemen verankert.
Eine strukturierte Ursache liegt vor: betroffene Services, Belege, empfohlene nächste Schritte, jeder Schritt protokolliert.
Ein Post-Mortem-Entwurf wird automatisch aus der Untersuchung erstellt: Verlauf, Ursache, beitragende Faktoren, To-dos.
Zeit bis zur Ursache: rund 6 Minuten
Jeder Schritt läuft innerhalb Ihres Clusters. Jede Abfrage, jeder Beleg, jeder Reasoning-Schritt ist protokolliert und nachvollziehbar.
Derselbe Kreislauf klinkt sich in die Tools ein, in denen Ihr Team ohnehin arbeitet, eingehend wie ausgehend.
Alerts, Chats und KI-Tools erreichen Hyground über Inbound-Adapter.
Ergebnisse kommen als Arbeit zurück, nicht als Benachrichtigung, in den Tools, die Ihr Team bereits nutzt.
Selbst gehostet & souverän
Hyground kommt als Kubernetes-Helm-Chart und läuft vollständig innerhalb Ihres Perimeters. Im Pfad sitzt kein Hyground-SaaS: keine Control Plane, kein Phone-home, kein Betreiberzugriff in Ihren Cluster.
Ein selbst gehostetes Helm-Chart ohne Zugriffspfad für den Anbieter. Keine SaaS-Control-Plane, kein zentraler Schlüssel, keine geteilte Infrastruktur. Der Anbieter hat keinen operativen Weg hinein.
Kein Daten-Egress, keine Telemetrie, kein Phone-home. Der einzige ausgehende Verkehr ist der Prompt an das von Ihnen gewählte LLM, und Secrets werden entfernt, bevor das Modell sie sieht. Hosten Sie dieses Modell selbst, verlässt überhaupt nichts mehr Ihre Infrastruktur.
Chainguard-Distroless-Images, non-root, schreibgeschütztes Root-Dateisystem. Adapter sind standardmäßig schreibgeschützt und verweigern den Start, wenn der Principal schreiben darf.

Testen Sie unsere Sandbox oder vereinbaren Sie eine Demo mit unserem Team und erleben Sie souveräne KI aus erster Hand.